
{kind=link}
Multimodal Humor Understanding
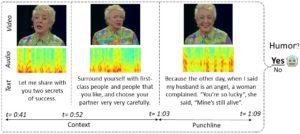
We introduce a multimodal dataset, UR-FUNNY, and a sequence of algorithms to recognize humor from 1866 videos featuring 1,741 TED Talks.
UR-FUNNY is the first humor-detection dataset that comprises all three modalities of text, vision, and audio. 8257 humorous punchlines are presented, along with the prior sentences that build up their respective contexts. As negative data samples, 8257 non-humourous excerpts are also presented, where the last sentences are not followed by laughter. Importantly, unlike previous datasets where negative samples were drawn from different domains, UR-FUNNY draws the negative samples from the same videos as the humorous ones.
The dataset is publicly available for download alongside all the extracted linguistic, acoustic, and visual features.
The essential question we ask is whether computational tools can predict if the excerpts from the videos are funny. A contextual memory fusion network is proposed, which achieves an accuracy of 65.23% in predicting whether the last sentence in a given excerpt consists of a punchline.
We introduce two algorithms: M-BERT and Humor Knowledge enriched Transformer (HKT) that can capture the gist of a multimodal humorous expression by integrating the preceding context and external knowledge and report state-of-the-art performance.
Publications
M. K. Hasan, S. Lee, W. Rahman, A. Zadeh, R. Mihalcea, L. P. Morency, E. Hoque, Humor Knowledge Enriched Transformer for Understanding Multimodal Humor, The Thirty-fifth AAAI Conference on Artificial Intelligence (AAAI-21), February 2021 [poster] [github]
W. Rahman, M. K. Hasan, S. Lee, A. Zadeh, C. Mao, LP Morency, M. E. Hoque, Integrating Multimodal Information in Large Pretrained Transformers, 2020 Annual Conference of the Association for Computational Linguistics (ACL), Seattle, July 2020.
M. K. Hasan, W. Rahman, A. Zadeh, J. Zhong, I. Tanveer, LP Morency, and M. E. Hoque, UR-FUNNY: A Multimodal Language Dataset for Understanding Humor, 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), Hong Kong, November 2019 [view poster]
Dataset
Please refer to https://github.com/ROC-HCI/UR-FUNNY for the data, processed features, and companion code.