Legion: Scribe
Real-time captioning converts aural speech into text within a few seconds. These captions provide access to aural speech for the nearly 40 million people in the United States who are deaf or hard of hearing (DHH) and other users who may be situationally disabled.
Currently, the only reliable source of real-time captions are stenographers who are trained to type phonemes into chording keyboards. This expertise makes their services expensive ($100-200/hr) and require scheduling in advance. One alternative is automatic speech recognition (ASR) which is less expensive and available on-demand, but its low accuracy, high noise sensitivity, and need for training beforehand render it unusable in real-world situations.
To help fill the gap left by these existing options, we introduced a new approach in which groups of non-expert captionists (anyone who can hear and type) collectively caption speech in real-time. The challenge is that a non-expert can’t keep with natural speaking rates, which can reach as high as 200-250 word per minute. Instead of requiring them to do so, we ask each person to type what they can and then merge the partial captions together into a final output.
We have found that an individual was only able to type an average of around 30% of the words spoken, which is roughly the same as ASR (though workers had much higher accuracy). However, collectively, 7 workers were able to capture as much as a professional – around 90%.
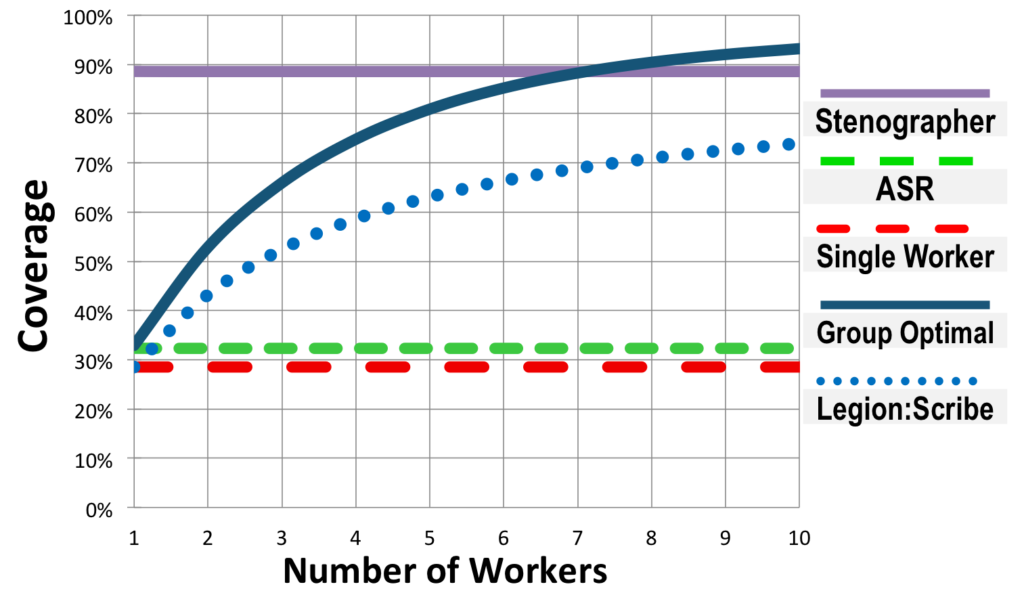
More recent work has improved over these initial results, showing that by better-directing workers to non-overlapping or minimally-overlapping portions of the speech, as few as 3-5 workers can meet or exceed the performance of a professional. Furthermore, Scribe’s framework is capable of using more than just human contributors. Since we found that ASR makes very different mistakes than human workers, we expect that these errors can be contrasted in such a way that the final output when using a hybrid set of contributors is superior to the output when using one exclusively.
Tests using Mechanical Turk showed that crowd workers could get 78% of the words spoken, even on longer clips, for a total cost of $36/hr to the user. Additionally, because the crowd provides a dynamic workforce, this service is available on-demand, and is billable by the minute not just by the hour as professionals are.
In summary, Scribe shows that the crowd may be able to provide a more reliable, low-cost, and convenient alternative to existing approaches for real-time captioning. In fact, our results suggest that the crowd may even be able to outperform experts on difficult cognitive and motor tasks. To us, this makes Scribe the most compelling application yet of the new model for human-computer interaction that we’ve been pursuing — one in which the crowd collectively acts as a single, high-performance individual.