NADBenchmarks – curating Benchmark Datasets for Machine Learning Tasks related to Natural Disasters
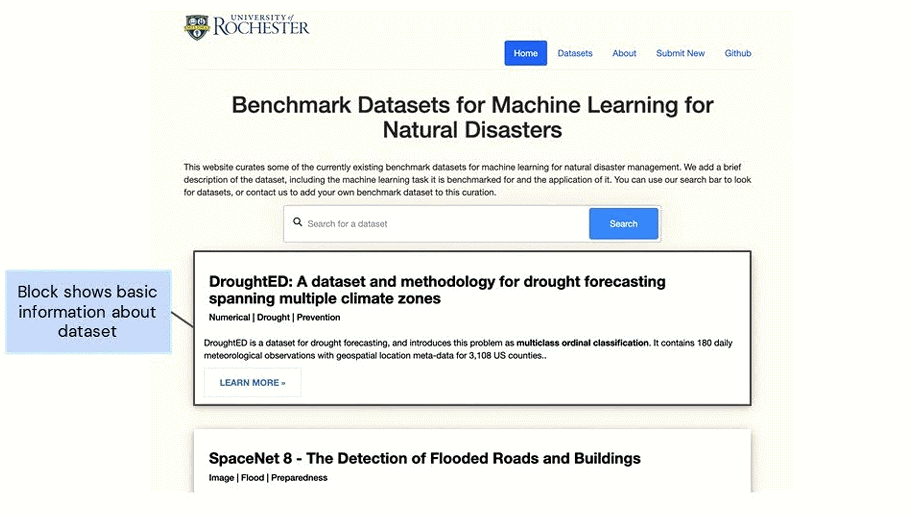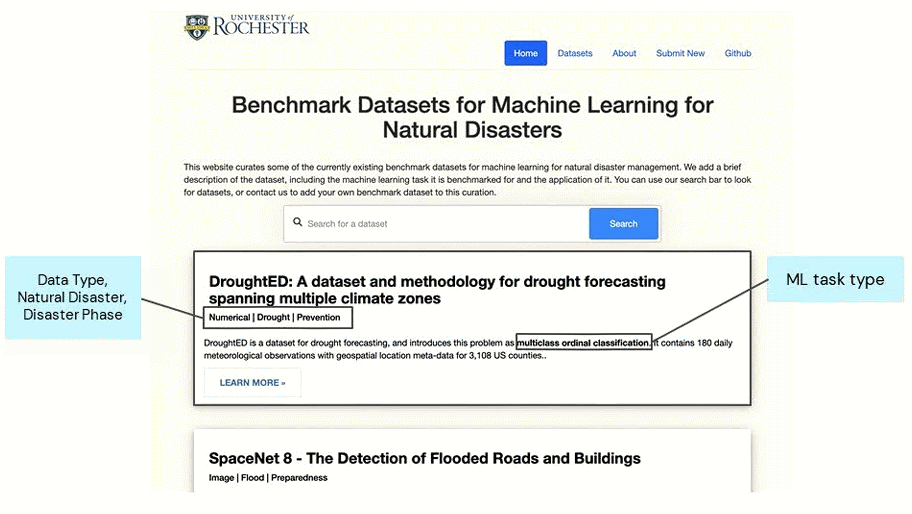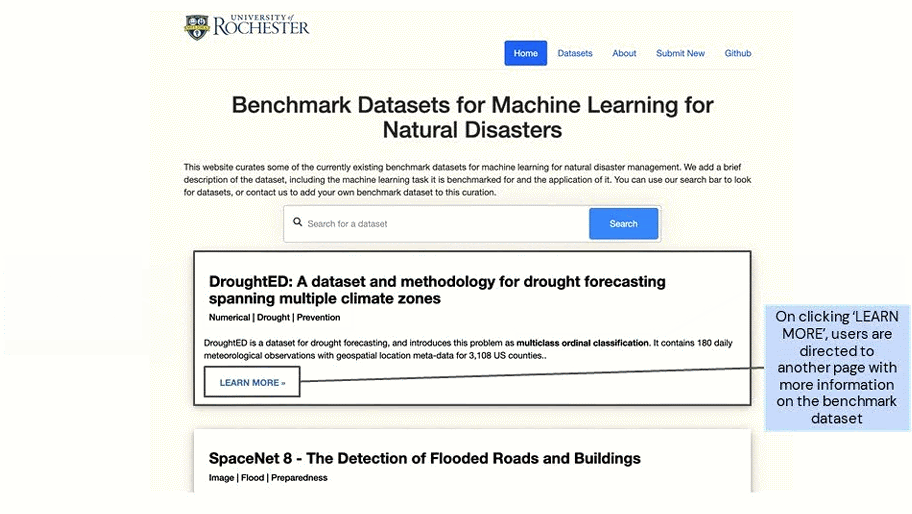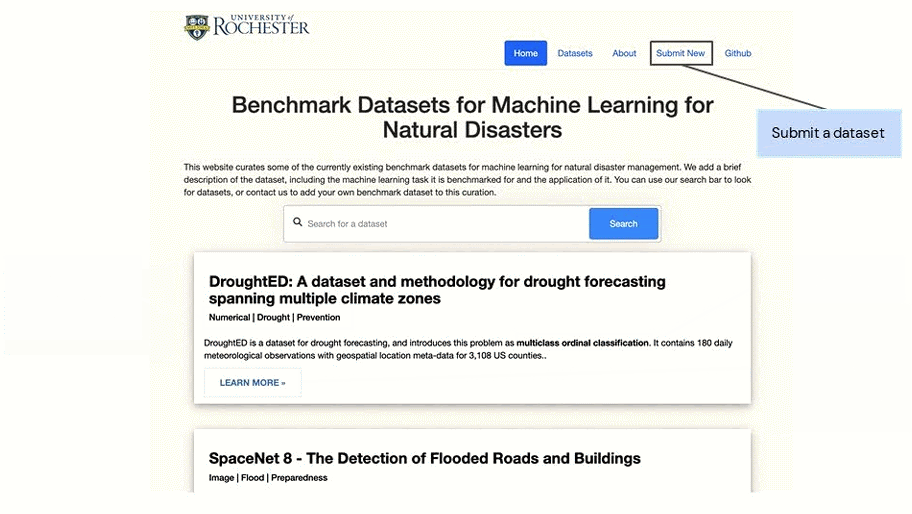
With climate change exacerbating the intensity, frequency, and duration of extreme weather events and natural disasters across the world, rapid advancement is required in its management. While the increased data on natural disasters improves the scope of machine learning (ML) for this field, to accelerate research, benchmark datasets can play a key role. Benchmark datasets are preprocessed, curated datasets for training and testing ML algorithms. These datasets provide scope for standard evaluation so that ML communities can quantify their progress and compare models. To facilitate research on natural disasters, we curate a list of existing benchmark datasets for natural disasters, categorizing them according to the disaster management cycle (mitigation, preparedness, responses and recovery). We develop a web platform – NADBenchmarks – where researchers can search for benchmark datasets for natural disasters. Currently, our curation covers the past five years. Our goal is to aid researchers in finding benchmark datasets to train their ML models on and also provide general directions for topics where they can contribute new benchmark datasets.
We encourage the community to submit their benchmark datasets related to natural disasters on our platform.
Website Link: https://natdisaster-datasets.ai/
Publications:
- A. Proma, M.S. Islam, S. Ciko, R.A. Baten and E. Hoque. “NADBenchmarks – a compilation of Benchmark Datasets for Machine Learning Tasks related to Natural Disasters.” AAAI Fall Symposium Series. 2022.